第15章 部署与运维
"造就'笔记本上跑得通'与'生产环境中可靠'之间差异的,不是某个大功能,而是一百个小细节——日志脱敏、优雅重启、非 root 执行、供应链验证。每个细节看起来都微不足道,直到你在凌晨三点需要它们。"
本章要点
- 掌握三种部署路径:裸机、Docker 多阶段构建、云平台
- 深入日志系统:结构化日志、敏感信息脱敏、滚动策略
- 理解重启管理与可观测性设计的工程实践
- 掌握 Dockerfile 构建优化的关键技巧
上一章我们掌握了与 OpenClaw 交互的方式——CLI 和 TUI。但无论界面多么精美,如果系统跑不起来、跑不稳定,一切都是空谈。本章从开发环境走向生产环境,解决"最后一公里"的工程问题。
在第 2 章的消息旅程中,我们追踪了一条消息从通道进入到响应返回的完整路径。那条路径假设 Gateway 已经在稳定运行。本章关注的是"旅程之前的旅程"——Gateway 如何被部署、如何保持运行、如何在出错时恢复、如何在不停机的情况下更新。
15.1 从演示到生产
15.1.1 鸿沟有多大
你的 Agent 在笔记本上完美运行。现在挑战来了:把它部署到 24/7 运行的云服务器上,服务跨通道用户,经受重启考验,产生干净日志而不泄露 API 密钥。
从"能用"到"稳定运行",就像从搭一座积木桥到建一座真正的桥——材料可能一样,但工程标准完全不同。积木桥倒了重搭就好,真正的桥上面跑着几千辆车。
15.1.2 生产环境的六个隐性需求
开发环境不需要但生产环境必须有的:
- 进程管理:崩溃后自动重启,优雅关闭不丢数据。
- 日志系统:结构化日志、自动脱敏、大小限制、滚动归档。
- 安全加固:非 root 运行、文件权限收紧、供应链验证。
- 资源控制:内存限制、磁盘配额、网络安全组。
- 可观测性:健康检查端点、状态监控、告警集成。
- 可重现性:相同的代码 + 相同的配置 = 相同的行为。
每一个需求看起来都"微小",但忽略其中任何一个都可能招来凌晨三点的告警电话。
🔥 深度洞察:部署是免疫系统,不是包装纸
大多数开发者把部署当作"把代码包装好放到服务器上"——一个后期附加步骤。这是根本性的误解。正确的类比来自医学:部署不是包装纸,而是免疫系统。人体的免疫系统不是在皮肤之外运作的,它渗透在每一个器官、每一条血管中——白细胞在血液中巡逻,淋巴结分布在全身,皮肤本身就是第一道屏障。同样,OpenClaw 的"生产就绪"不是最后一步涂上的外壳,而是从第一行代码就开始渗透的品质:日志脱敏规则决定了配置文件的格式(SecretRef 而非明文),重启延迟策略影响了 LLM 调用的超时设计,Docker 的非 root 约束影响了文件路径的选择。生产环境不会原谅"先跑通再加固"的思维——因为加固不是附加层,而是骨骼结构本身。
15.1.3 部署架构的演进
OpenClaw 的部署模型经历了三个阶段的演进,每个阶段对应了用户群体和使用场景的扩大:
第一阶段:裸机直接运行。开发者在自己的机器上 npm install -g openclaw && openclaw gateway start。简单直接,但没有进程管理——终端关了,Agent 就停了。
第二阶段:系统服务化。引入 src/daemon/ 模块,支持 systemd/launchd/schtasks 三平台服务管理。Agent 变成了真正的守护进程——开机自启、崩溃重启、后台运行。这是大多数个人用户和小团队的最佳选择。
第三阶段:容器化部署。Docker 镜像 + Compose 编排。适合需要环境隔离、可复现部署或云平台部署的场景。代价是额外的容器管理开销。
为什么三个阶段共存而不是只保留最新的? 因为不同用户有不同的运维能力和部署需求:
- 个人开发者用裸机模式就够了——简单、直接、零开销
- 小团队用系统服务——可靠但不需要 Docker 知识
- 企业部署用容器——环境隔离、CI/CD 集成、基础设施即代码
OpenClaw 不强制用户接受不需要的复杂性。
关键概念:渐进式部署(Progressive Deployment) OpenClaw 的部署模型遵循渐进式复杂度原则——从最简单的裸机全局安装(零 Docker 知识),到系统服务化(Daemon 管理),再到容器化部署(Docker + Compose)。每一层都是可选的,用户只需承担其实际需求对应的复杂度。这与"全部容器化"的一刀切方案形成鲜明对比。
15.2 裸机部署:最简路径
15.2.1 全局安装
npm install -g openclaw
# 或
bun install -g openclawOpenClaw 同时支持 Node.js(22+)和 Bun 运行时。选择 Bun 的理由通常是启动速度——Bun 的启动时间约 50ms,Node.js 约 200ms。对于 Daemon 来说这个差异可以忽略(只启动一次),但在 CLI 命令中(每次执行都启动一个新进程),150ms 的差异是可感知的。
15.2.2 首次配置
openclaw # 首次运行自动启动配置向导
# 或
openclaw setup # 显式启动配置向导配置向导(第 14 章 14.8 节)引导用户完成:
- Provider 选择和认证配置
- 通道启用和 token 设置
- 安全策略确认
- 测试连接
配置文件生成在 ~/.openclaw/config.json5(或 $OPENCLAW_CONFIG 指定的路径)。
15.2.3 系统服务注册
openclaw gateway start --install # 安装并启动系统服务这一条命令做了以下事情:
- 检测当前操作系统和可用的服务管理器
- 生成对应的服务配置(systemd unit / launchd plist / schtasks XML)
- 注册服务并启动
- 验证服务正常运行
Linux systemd 的具体实现:
src/daemon/systemd-unit.ts 生成的 unit 文件:
[Unit]
Description=OpenClaw Gateway
After=network-online.target
Wants=network-online.target
[Service]
Type=exec
ExecStart=/usr/bin/node /usr/lib/node_modules/openclaw/openclaw.mjs gateway start --foreground
Restart=on-failure
RestartSec=5
Environment=NODE_ENV=production
[Install]
WantedBy=default.target几个关键配置决策:
Type=exec(而非simple):确保 systemd 等待进程完全启动后才认为服务就绪After=network-online.target:Gateway 需要网络来连接通道和 LLM API,必须在网络就绪后才启动Restart=on-failure(而非always):正常退出(exit code 0)不重启,异常退出才重启——避免"用户手动停止后服务又自动启动"的困扰RestartSec=5:5 秒重启延迟,防止快速失败循环(crash loop)耗尽系统资源
systemd-linger.ts 的必要性。默认情况下,systemd 会在用户注销时停止其用户服务。loginctl enable-linger 让服务在用户注销后继续运行——这对无人值守的服务器至关重要。OpenClaw 会检测 linger 状态,如果未启用则提示用户。
15.2.4 裸机部署的局限
裸机部署的主要风险是环境依赖:
- Node.js 版本不匹配(OpenClaw 要求 22+,系统可能只有 18)
- 系统库缺失(Chromium 需要特定的 X11/Wayland 库)
- 权限问题(npm 全局安装可能需要 sudo)
这些问题正是容器化要解决的。
⚠️ 注意:裸机部署时,务必使用
loginctl enable-linger确保 systemd 用户服务在 SSH 断开后继续运行。否则关闭 SSH 会话后,Gateway 守护进程会被 systemd 自动终止——这是新部署中最常见的"Agent 突然失联"问题。
💡 最佳实践:生产环境部署推荐使用非 root 用户运行 OpenClaw。创建专用用户
useradd -m openclaw,将配置文件权限设为600(仅 owner 可读写),避免 API 密钥被其他用户读取。
15.3 Docker:多阶段构建工程
15.3.1 四阶段构建
OpenClaw 的 Dockerfile 使用四阶段构建——不是"从简单到复杂"的演进,而是对构建效率和镜像安全的精细工程:
图 15-1:四阶段 Docker 构建流程
下图展示了 OpenClaw Docker 镜像的四阶段构建流程:阶段 1 安装 npm 依赖(利用 Docker 层缓存加速),阶段 2 编译 TypeScript,阶段 3 剔除 devDependencies 和构建产物只保留生产文件,阶段 4 基于最小基础镜像生成最终运行镜像。这种分阶段设计使最终镜像体积减小约 60%。
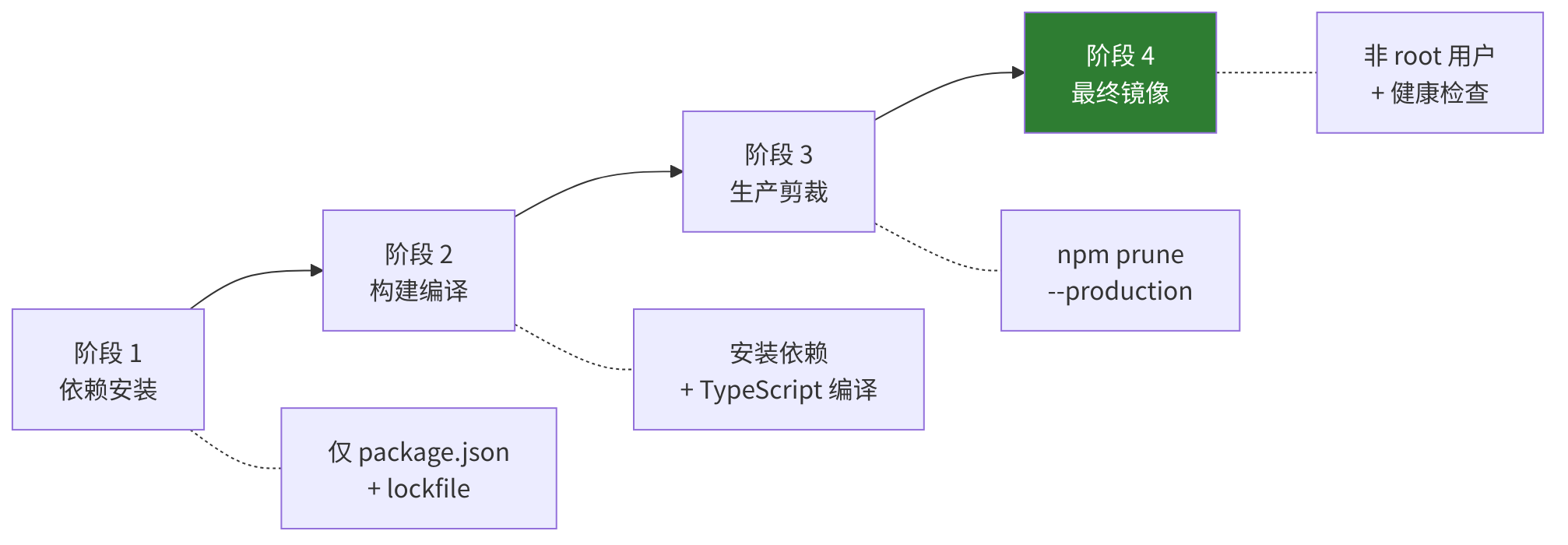
阶段1:依赖安装。仅复制 package.json 和 package-lock.json,不复制源码。这利用了 Docker 的层缓存——源码变更不会使 npm install 缓存失效。典型的代码修改从 ~5 分钟降到 ~30 秒重建。
# 阶段 1:只复制依赖描述文件
COPY package*.json ./
RUN npm ci --frozen-lockfile为什么用 npm ci 而不是 npm install?ci 命令严格按照 package-lock.json 安装,不会更新 lockfile。这确保了构建的可重现性——无论何时何地构建,安装的依赖版本完全一致。
阶段2:构建。安装依赖和编译 TypeScript。包括 Bun 安装重试(5 次指数退避——Bun CDN 偶尔不稳定)和 BuildKit 缓存挂载。
# 阶段 2:复制源码并构建
COPY . .
RUN npm run build阶段3:生产剪裁。npm prune --production 移除开发依赖和构建工具。这一步可以将 node_modules 从 ~500MB 缩减到 ~200MB。
# 阶段 3:移除开发依赖
RUN npm prune --production这个步骤的效果非常显著——这一步移除 TypeScript 编译器(~60MB)、测试框架、lint 工具、类型声明等全部开发依赖。它们在生产环境中完全无用,但在不剪裁的情况下会显著增加镜像体积和攻击面。
阶段4:最终运行时镜像。非 root 执行(USER node)、内建健康检查。
# 阶段 4:最终镜像
FROM node:22-slim
COPY --from=build /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
USER node
HEALTHCHECK --interval=30s --timeout=3s \
CMD curl -f http://localhost:18789/health || exit 115.3.2 两个镜像变体
| 变体 | 包含 | 镜像大小 | 用途 |
|---|---|---|---|
default | Node.js + Chromium + Playwright | ~1.2GB | 需要浏览器自动化(截图、网页操作) |
slim | 仅 Node.js | ~300MB | 不需要浏览器,纯文本 Agent |
为什么提供两个变体? Chromium 占据了镜像体积的 70%(~900MB)。如果 Agent 不需要浏览器自动化(很多纯对话型 Agent 不需要),强制包含 Chromium 是浪费——更慢的拉取、更大的存储、更大的攻击面。
选择建议:
- 你的 Agent 需要
browser工具(截图、网页浏览、表单填写)→ 用default - 你的 Agent 只需要文本对话、Shell 执行、Web 搜索 → 用
slim
15.3.3 供应链安全加固
GPG 指纹验证:Docker CLI 安装时验证 GPG 签名指纹,防止供应链攻击——即使攻击者入侵了安装源,签名不匹配也会导致安装失败。
# 验证 Docker GPG 签名
RUN gpg --verify docker.gpg && \
gpg --fingerprint | grep -q "EXPECTED_FINGERPRINT"--frozen-lockfile:确保 npm install 使用与开发环境完全相同的依赖版本。没有这个标志,npm install 可能静默升级依赖,导致"在我机器上好好的"问题。
非 root 执行:容器内进程以 node 用户运行,即使攻击者突破容器,也没有 root 权限。这是纵深防御的一部分(呼应第 13 章的安全哲学)——容器隔离是一道防线,非 root 是另一道,两者独立生效。
15.3.4 Docker Compose 双容器编排
services:
gateway:
# 网关持久运行
restart: unless-stopped
cap_drop: [NET_RAW, NET_ADMIN]
security_opt: ["no-new-privileges"]
volumes:
- openclaw-data:/home/node/.openclaw
ports:
- "18789:18789"
cli:
# CLI 按需启动
profiles: [cli] # 不随 docker compose up 启动
depends_on: [gateway]
volumes:
- openclaw-data:/home/node/.openclaw
volumes:
openclaw-data:为什么双容器而不是单容器? 延续了第 14 章的"守护进程 + 客户端"架构——Gateway 容器持久运行,CLI 容器按需启动(docker compose run --rm cli openclaw config validate)。两者共享同一个数据卷,保证状态一致。
安全配置详解:
| 配置 | 含义 | 防护目标 |
|---|---|---|
cap_drop: [NET_RAW] | 移除原始网络访问能力 | 防止端口扫描和网络嗅探 |
cap_drop: [NET_ADMIN] | 移除网络配置能力 | 防止修改路由表、防火墙规则 |
no-new-privileges | 禁止通过 setuid 提权 | 防止利用 suid 二进制提升权限 |
restart: unless-stopped | 崩溃自动重启,手动停止不重启 | 确保服务可用性 |
cap_drop 移除了不需要的 Linux 能力——网关不需要原始网络访问(NET_RAW)或网络配置(NET_ADMIN)。这遵循最小权限原则——进程只应该拥有完成工作所需的最小权限集。
15.3.5 容器化 vs 裸机的深度对比
| 维度 | 裸机部署 | 容器化部署 |
|---|---|---|
| 启动速度 | ~200ms(直接启动) | ~1-2s(容器开销) |
| 环境隔离 | 无——共享主机环境 | 完全隔离——独立文件系统和网络 |
| 资源占用 | 最小——无容器运行时开销 | 中等——Docker daemon 占用 ~100MB |
| 可重现性 | 依赖主机环境配置 | 完全可重现——镜像即环境 |
| 升级回滚 | 手动——需要备份和恢复 | 简单——切换镜像版本即可 |
| 调试便利性 | 高——直接 strace、gdb | 中——需要 docker exec 进入容器 |
| 多实例 | 需要手动管理端口和配置 | 简单——Compose 原生支持 |
| 日志管理 | 需要自行配置 logrotate | Docker 内建日志驱动 |
什么时候选裸机?
- 个人开发机——简单直接,调试方便
- 资源受限的设备(如树莓派)——Docker 开销不可忽视
- 需要直接访问 GPU——Docker GPU 透传配置复杂
什么时候选容器?
- 生产部署——环境一致性和可重现性是刚需
- CI/CD 集成——容器是标准构建产物
- 多实例部署——需要在同一主机运行多个 Gateway
- 团队协作——"在我机器上好好的"不应该是问题
15.4 云平台部署
15.4.1 Fly.io 部署
Fly.io 是 OpenClaw 社区推荐的云部署方案之一,因为它对长连接友好(WhatsApp/Discord 等通道需要维持 WebSocket 连接)。
关键配置:
[http_service]
auto_stop_machines = false # ⚠️ 关键!
min_machines_running = 1auto_stop_machines = false 至关重要——网关维护与消息平台的持久 WebSocket 连接。Fly.io 的自动停止功能会切断所有通道连接,导致 Agent 变成"聋子"——看不到任何消息。
持久存储:
Agent 需要持久存储来保存会话状态、Cron 作业历史和安全审计日志。Fly.io 的 volumes 提供持久磁盘,但只在单机器部署时可用——这限制了水平扩展,但对于 OpenClaw 的单运营者假设是可接受的。
15.4.2 VPS 部署(通用方案)
对于不使用 PaaS 的场景(AWS EC2、DigitalOcean Droplet、Hetzner VPS),部署流程:
# 1. 安装 Node.js 22+
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt-get install -y nodejs
# 2. 安装 OpenClaw
npm install -g openclaw
# 3. 配置
openclaw setup --non-interactive \
--provider anthropic \
--api-key "$ANTHROPIC_API_KEY"
# 4. 注册为系统服务
openclaw gateway start --install
# 5. 验证
openclaw gateway status
openclaw doctor网络安全考量:
Gateway 默认监听 0.0.0.0:18789。在生产环境中,你应该:
- 使用防火墙(
ufw/iptables)限制 18789 端口的访问来源 - 或者绑定到
127.0.0.1并通过反向代理(Nginx/Caddy)暴露 - 通道连接(Telegram、Discord 等)是出站连接,不需要入站端口
15.4.3 移动端伴侣应用部署
OpenClaw 还支持通过移动端 companion app(iOS/Android/macOS)扩展 Agent 的感知能力(第 11 章)。这些 app 通过 WebSocket 连接到 Gateway,需要 Gateway 的地址可达。部署方案的选择会影响移动端连接:
- 本地网络:Gateway 和 app 在同一局域网——直接通过 LAN IP 连接
- Tailscale/ZeroTier:跨网络部署——通过 VPN 打通 Gateway 和 app
- 公网部署:Gateway 有公网 IP——app 直接连接(需要 TLS)
15.5 日志系统:结构化、脱敏、滚动
15.5.1 日志系统的设计哲学
日志不是"调试完就删除的 console.log"——它是系统的飞行记录仪。OpenClaw 的日志系统设计遵循三个原则:
- 结构化优先:日志是数据,不是文本。可查询、可聚合、可告警
- 安全默认:敏感信息自动脱敏,不需要开发者记得"这里不能打印 API Key"
- 永不崩溃:日志系统的故障不应该影响核心功能
15.5.2 三个目的
日志系统同时服务三个目的,每个目的对日志格式和内容有不同需求:
| 目的 | 需求 | OpenClaw 的实现 |
|---|---|---|
| 调试 | 详细上下文、堆栈追踪、请求/响应对 | 分级日志(debug/info/warn/error) |
| 审计 | 谁做了什么、什么时候、结果如何 | 结构化字段 + 时间戳 |
| 监控 | 结构化字段、可查询、可告警 | JSON Lines + 外部 transport |
15.5.3 日志基础设施
src/logging/logger.ts 是日志系统的核心。它基于 tslog 库构建,但添加了大量 OpenClaw 特有的功能:
// src/logging/logger.ts(简化)
export const DEFAULT_LOG_DIR = resolveDefaultLogDir();
export const DEFAULT_LOG_FILE = resolveDefaultLogFile(DEFAULT_LOG_DIR);
const MAX_LOG_AGE_MS = 24 * 60 * 60 * 1000; // 24h
const DEFAULT_MAX_LOG_FILE_BYTES = 500 * 1024 * 1024; // 500 MB双输出架构。每条日志同时写入两个目标:
- 文件:JSON Lines 格式,完整的结构化数据
- 控制台:人类可读的着色文本
两个输出有独立的级别控制——控制台可以设为 warn(只看重要的),文件设为 debug(记录一切)。
子系统着色。每个子系统(gateway、cron、browser、security)有独立的日志器,通过字符串哈希确定性分配颜色:
[12:34:56] [gateway] ■ Server listening on 0.0.0.0:18789
[12:34:57] [cron] ■ Loaded 3 cron jobs
[12:34:57] [browser] ■ Chromium path: /usr/bin/chromium
[12:34:58] [security]■ Audit: 0 critical, 2 warnings哈希着色保证同一个子系统的颜色在每次运行中一致——gateway 永远是蓝色,security 永远是红色。这让运维人员在快速扫描日志时可以用颜色过滤信息。
15.5.4 JSON Lines 格式
每行一个完整 JSON 对象——支持 jq 过滤和日志平台(Datadog、ELK Stack)摄入。
{"ts":"2026-03-21T10:15:30Z","level":"info","subsystem":"cron","msg":"作业执行完成","jobId":"daily-report","durationMs":3200}
{"ts":"2026-03-21T10:15:31Z","level":"warn","subsystem":"gateway","msg":"通道重连","channel":"discord","attempt":3}为什么用 JSON Lines 而不是多行 JSON?因为 JSON Lines 是可追加的——新日志直接 append 到文件末尾,不需要解析和重写整个文件。这对于高频写入的日志文件至关重要。而且 jq 原生支持 JSON Lines,运维友好。
15.5.5 自动脱敏
17 种模式类别自动掩码日志中的敏感值(src/logging/redact.ts):
// 自动检测并掩码
`sk-proj-ABCDEF...XYZ` → `sk-pro…XyZ8` // OpenAI 密钥
`ghp_1234567890abcdef` → `ghp_12…cdef` // GitHub PAT
`bot123456:ABC-DEF_GH` → `bot123…F_GH` // Telegram Bot Token
`xoxb-123456-789-abc` → `xoxb-1…-abc` // Slack Bot Token
`SG.xxx.yyy` → `SG.xx…yyy` // SendGrid API Key
`AKIA*************` → `AKIA**…****` // AWS Access Key掩码算法保留前 6 个和后 4 个字符——足以识别是哪个密钥(当你有多个时),但不足以重建完整密钥。短密钥(<18 字符)完全替换为 ***。
为什么需要 17 种模式? 每个服务的 API Key 格式不同:
- OpenAI 以
sk-开头 - Anthropic 以
sk-ant-开头 - GitHub PAT 以
ghp_开头 - AWS 以
AKIA开头
通用的"替换看起来像密钥的字符串"方法误报率极高(正常的 base64 编码数据也会被误掩)。OpenClaw 为每种已知密钥格式编写精确的正则表达式,在准确性与覆盖率之间精确走钢丝。
脱敏与第 13 章的 SecretRef 的关系。SecretRef(第 13 章)确保密钥不出现在配置文件中。日志脱敏确保密钥不出现在日志文件中。两者是互补的——SecretRef 防止静态泄露,脱敏防止运行时泄露。
15.5.6 日志失败永不崩溃
// src/logging/logger.ts(概念)
try {
fs.appendFileSync(logFile, line + "\n");
} catch {
// 静默丢弃——日志失败不应影响核心功能
}每次日志写入包裹在 try-catch 中。磁盘满时静默丢弃消息而非崩溃网关。
为什么日志失败不应该崩溃? 日志是辅助功能——Agent 的核心功能(响应消息、执行工具、管理会话)不依赖日志。因为日志写入失败而停止 Agent 服务,就像因为行车记录仪坏了而熄火停车——你的乘客可不会觉得这是"安全设计"。
更深层的原因是:日志写入失败最常见的原因是磁盘满。此时系统已经处于异常状态。如果因此崩溃,重启后磁盘仍然是满的,服务会陷入 crash loop。静默丢弃让服务继续运行,运维人员有时间处理磁盘问题。
15.5.7 滚动与大小限制
// src/logging/logger.ts
const MAX_LOG_AGE_MS = 24 * 60 * 60 * 1000; // 24 小时
const DEFAULT_MAX_LOG_FILE_BYTES = 500 * 1024 * 1024; // 500 MB- 文件名按日期:
openclaw-2026-03-21.log——每天一个新文件 - 24 小时后修剪旧日志——自动清理过期日志
- 500MB 大小上限——防止失控日志填满磁盘
为什么是 500MB?这是经验数据——高频对话场景(每秒数条消息)下,24 小时日志量约 200-300MB。500MB 留出 60% 安全余量,不多不少。
与外部日志系统的集成。src/logging/logger.ts 支持外部 transport:
// 外部 transport 注册
const externalTransports = new Set<LogTransport>();
function attachExternalTransport(logger: TsLogger<LogObj>, transport: LogTransport): void {
logger.attachTransport((logObj: LogObj) => {
if (!externalTransports.has(transport)) return;
try {
transport(logObj as LogTransportRecord);
} catch {
// never block on logging failures
}
});
}这让插件可以将日志转发到 Datadog、Grafana Loki、ELK Stack 等外部系统,实现集中式日志管理。transport 的错误不会影响日志系统本身——又一次"永不崩溃"原则的体现。
15.5.8 环境变量日志级别覆盖
src/logging/env-log-level.ts 支持通过环境变量覆盖日志级别:
OPENCLAW_LOG_LEVEL=debug openclaw gateway start --foreground这对调试生产问题至关重要——不需要修改配置文件并重启,只需设置环境变量并启动一个前台进程即可。
特殊的 Vitest 快速路径。在测试环境中(VITEST=true),日志系统走一条特殊的快速路径——跳过文件写入和颜色渲染,避免测试因日志 I/O 变慢。这个细节体现了"日志系统不应该拖慢任何东西"的设计原则。
15.6 重启管理
15.6.1 为什么重启不是"停止 + 启动"
天真的重启实现是 stop && start。但在 Agent 系统中,这有两个严重问题:
- LLM 调用中断:一次 LLM 调用可能持续 30 秒到 3 分钟。如果在调用进行中重启,用户会丢失这次(可能已经消耗了大量 token 的)响应。
- 通道连接重建:WhatsApp、Discord 等通道的连接重建需要时间(3-30 秒),在此期间消息会丢失。
OpenClaw 的重启管理系统解决了这两个问题。
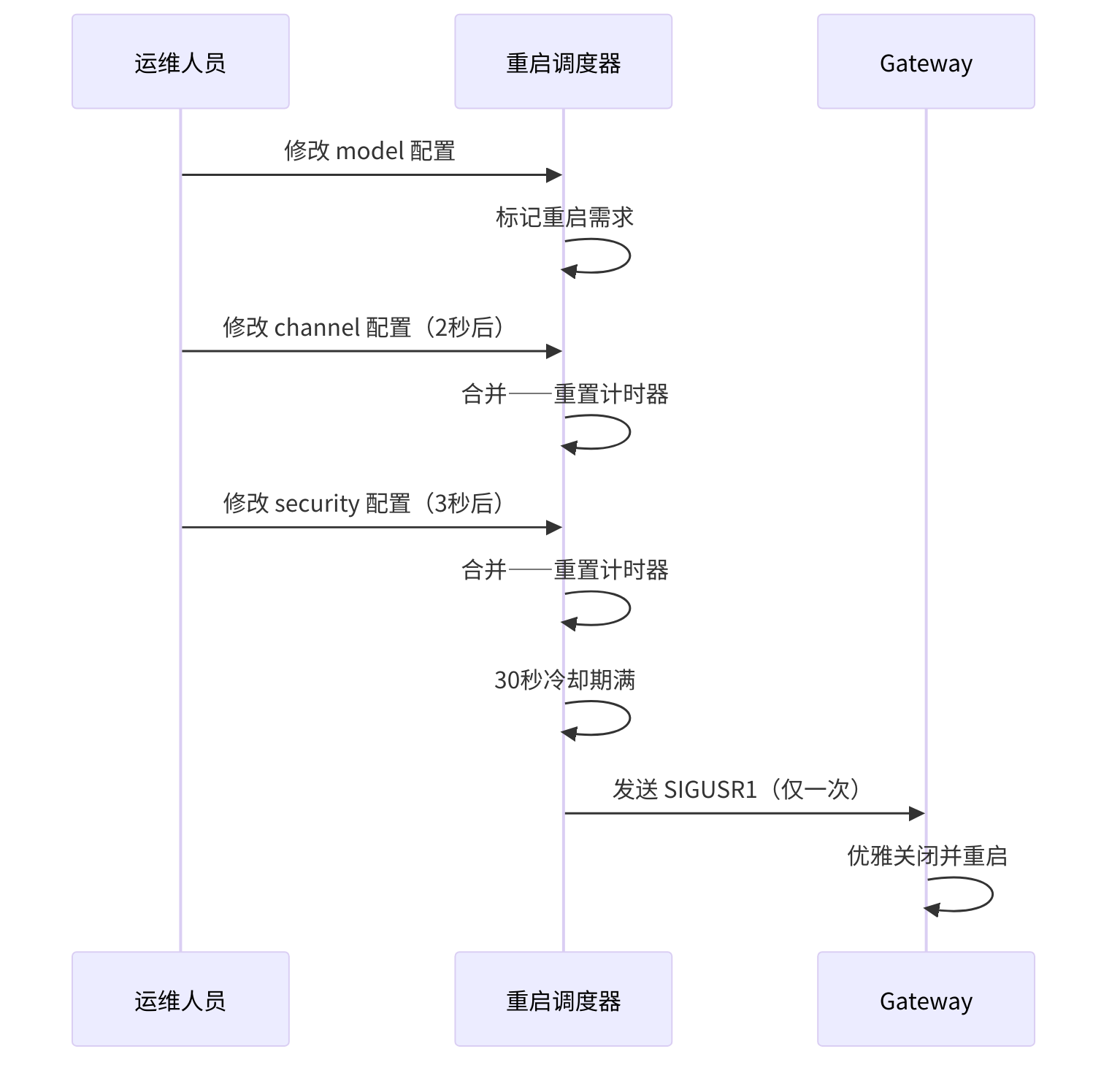
15.6.2 SIGUSR1 信号
为什么选择 SIGUSR1 而非其他信号?
| 信号 | 问题 |
|---|---|
| SIGHUP | 终端断开时自动发送——SSH 断开会意外重启 |
| SIGTERM | 默认终止进程——系统可能在重启逻辑执行前杀掉进程 |
| HTTP API | 需要自己的认证层,重启期间 API 不可用 |
| SIGUSR1 | ✅ 用户定义信号,无默认行为,完全由应用控制 |
收到 SIGUSR1 后,Gateway 进入"优雅关闭"流程:
- 停止接受新的 Agent 请求
- 等待进行中的 LLM 调用完成(最多 5 分钟)
- 保存所有会话状态
- 关闭通道连接
- 退出进程
系统服务管理器(systemd/launchd)检测到进程退出后会自动重新启动——完成"重启"的后半段。
15.6.3 延迟重启
重启不会中断进行中的 LLM 调用——系统等待最多 5 分钟让它们完成。用户不会因为配置变更而失去一个耗时 3 分钟的 Agent 回复。
5 分钟超时的由来。实测表明,99% 的 LLM 调用在 3 分钟内收工(含多轮工具调用循环)。5 分钟留出 67% 安全余量。超过 5 分钟?十有八九是某个工具卡死了——强制重启反而是正解。
15.6.4 请求合并
快速配置变更不会触发多次重启。调度器合并重复请求,遵守 30 秒冷却期——5 秒内修改了 3 次配置只触发 1 次重启。
15.6.5 跨平台服务管理
Linux → systemctl --user restart openclaw-gateway
macOS → launchctl kickstart(+ bootstrap 回退)
Windows → schtasks(计划任务立即执行)统一的 openclaw gateway restart 命令在所有平台上工作,底层适配不同的服务管理器。
macOS launchctl 的历史包袱。macOS 的 launchctl 在不同版本中有不同的子命令语法——老版本用 launchctl load/unload,新版本用 launchctl bootstrap/bootout。src/daemon/launchd.ts 同时处理两种语法,并在失败时自动回退。
15.7 可观测性设计
15.7.1 健康检查端点
Gateway 在 http://localhost:18789/health 提供健康检查端点。返回的不是简单的 200 OK,而是结构化的健康状态:
{
"status": "healthy",
"uptime": 86400,
"channels": {
"telegram": "connected",
"discord": "connected",
"whatsapp": "reconnecting"
},
"activeSessions": 5,
"activeRuns": 2
}这让监控系统不只知道"进程活着",还知道"各通道是否正常"。WhatsApp 正在重连?等 30 秒再检查。Discord 断开了?发告警。
15.7.2 通道健康监控
src/gateway/channel-health-monitor.ts(第 3 章详述)守护通道级健康。每个通道独立追踪健康状态,断连后指数退避自动重连(5s → 10s → 20s → … → 上限 5 分钟)。
这与 Docker 的容器健康检查形成互补:
- Docker 健康检查回答:"Gateway 进程还活着吗?"
- 通道健康监控回答:"Gateway 的 Telegram 通道还工作吗?"
两者缺一不可——Gateway 进程可能活着但 Telegram 通道已断开(API token 过期),或者 Telegram 通道正常但 Gateway 即将耗尽内存。
15.7.3 配置变更审计
系统记录每次配置变更——不只是"配置发生了修改",还包括"哪个字段从什么值变成了什么值"。src/gateway/config-reload.ts 的 diffConfigPaths 函数计算精确的配置差异。
这对于生产事故的事后分析至关重要:"Agent 在 10:15 开始行为异常——检查日志发现 10:12 有一次配置变更,将默认模型从 claude-opus 改成了 gpt-4o,导致工具调用格式不兼容。"
15.8 基础设施模块
15.8.1 SSRF 防护
阻止 Agent 控制的工具(如 web_fetch、browser)访问内部网络资源。src/infra/net/ssrf.ts 中的 isBlockedHostnameOrIp() 检查:
127.0.0.1、::1(回环地址)10.0.0.0/8、172.16.0.0/12、192.168.0.0/16(私有网络)169.254.0.0/16(链路本地,包括 AWS 元数据169.254.169.254)fd00::/8(IPv6 唯一本地地址)
最后一个特别重要——AWS 的实例元数据服务在 169.254.169.254 上,包含 IAM 角色凭证。如果 Agent 能访问这个地址,等于获得了实例的 AWS 权限。SSRF 防护是部署在云环境中的 Agent 系统的必须项,不是可选项。
与第 13 章安全系统的关系。SSRF 防护是安全系统在网络层的延伸。第 13 章的安全审计会检测 SSRF 防护是否启用——一旦禁用,即产生 critical 级别的审计发现。
15.8.2 文件锁
跨进程顾问锁防止并发网关实例损坏共享状态。如果运营者意外启动了两个 openclaw gateway start,文件锁确保第二个实例检测到冲突并退出,而非两个实例竞争同一个配置和状态目录。
$ openclaw gateway start
Error: Another Gateway instance is already running (PID: 12345).
Stop it first: openclaw gateway stop文件锁使用 flock(Linux/macOS)或 LockFileEx(Windows)实现,这些是操作系统级别的原子锁——即使进程崩溃也会自动释放。
15.8.3 状态迁移
OpenClaw 更新改变数据格式时,启动时自动无损升级。迁移遵循"只前进不后退"的原则——状态一旦升级到 v3,就无法降级回 v2。
这与数据库迁移(如 Rails 的 db:migrate)类似,但更简单——因为 OpenClaw 的状态存储是文件系统(JSON/JSONL),迁移逻辑就是读取旧格式、转换为新格式、写入。
迁移的原子性。迁移过程使用"写入临时文件 → 原子重命名"的模式。如果迁移过程中进程崩溃,下次启动时检测到临时文件,重新执行迁移。这确保了状态文件要么是旧格式(未迁移)要么是新格式(迁移完成),不会出现"半迁移"状态。
15.8.4 备份系统
src/infra/backup-create.ts 和 src/infra/archive-*.ts 驱动状态目录的自动备份:
openclaw backup create # 创建当前状态的快照
openclaw backup restore latest # 从最新备份恢复备份范围包括:
- 配置文件
- 会话历史
- Cron 作业定义
- 安全策略
- 技能快照
不包括:日志文件(太大且时效性强)、临时文件、缓存。
15.8.5 重试基础设施
src/infra/backoff.ts 封装了带完全抖动的指数退避策略,用于 LLM API 调用、通道重连等场景:
// src/infra/backoff.ts
delay = random(0, min(maxDelay, baseDelay * 2^attempt))为什么用"完全抖动"而非"等量抖动"?
等量抖动: delay = baseDelay * 2^attempt / 2 + random(0, baseDelay * 2^attempt / 2)
完全抖动: delay = random(0, baseDelay * 2^attempt)"完全抖动"(Full Jitter)的延迟范围更大(从 0 开始),更均匀地分散重试时间。当 100 个客户端同时因为 API 限速而重试时:
- 等量抖动:所有客户端的延迟都在
[T/2, T]范围内——仍然很集中 - 完全抖动:延迟在
[0, T]范围内——分散效果好得多
这就是"惊群效应"(Thundering Herd)的解决方案——100 个人同时被闹钟叫醒冲向咖啡机,不如让他们在随机时间自然醒来。AWS 的文章《Exponential Backoff and Jitter》是这一策略的经典参考。
15.8.6 性能优化实践
部署到生产环境后,性能调优是持续运维的核心关注点。OpenClaw 涉及的性能维度与传统 Web 服务有显著不同——Token 消耗是首要成本项,延迟敏感度极高,而并发模型受限于 LLM API 的速率限制。
Token 优化策略
Token 是 LLM 调用的"货币",每一个多余的 Token 都直接转化为成本和延迟。以下是经过验证的优化实践:
| 策略 | 实现方式 | 预期效果 |
|---|---|---|
| 系统提示精简 | 用 Token 计数工具审查 SOUL.md 和 AGENTS.md,移除冗余指令 | 每轮对话节省 500-2000 token |
| 技能按需加载 | 依赖第 16 章的按需加载机制,避免预注入所有技能 | 减少 60-80% 的技能 Token 占用 |
| 上下文压缩 | 配置 agentContextTokens 上限,触发第 5 章的自动压缩 | 长对话成本降低 40-60% |
| 工具输出截断 | 利用工具策略管线(第 10 章)的输出限制,避免巨大工具输出涌入上下文 | 避免单次调用的 Token 爆炸 |
| 模型分级使用 | 轻量任务(分类、路由)使用小模型,复杂推理使用大模型 | 总成本降低 50%+ |
# 监控 Token 消耗的实用命令
# 查看最近 24 小时的 Token 使用量(从 JSON Lines 日志提取)
cat ~/.openclaw/logs/gateway.log | jq -r \
'select(.usage) | [.timestamp, .model, .usage.input, .usage.output, .usage.total] | @tsv' \
| tail -50
# 按模型汇总 Token 使用
cat ~/.openclaw/logs/gateway.log | jq -r \
'select(.usage) | .model + "\t" + (.usage.total | tostring)' \
| sort | awk -F'\t' '{sum[$1]+=$2} END{for(m in sum) print m, sum[m]}' | sort -k2 -rn流式响应延迟优化
用户感知的延迟由两部分组成:首 Token 延迟(Time-to-First-Token, TTFT) 和 Token 间延迟(Inter-Token Latency, ITL)。
优化首 Token 延迟的关键措施:
- 选择地理位置接近的 API 端点:网络往返时间直接叠加到 TTFT
- 启用 Provider 缓存:Anthropic 的 prompt caching(第 4 章
cache_read_input_tokens)可将重复前缀的 TTFT 降低 80% - 减少系统提示体积:更短的 prompt 意味着更快的首 Token 到达
- 使用流式模式(
stream: true):OpenClaw 默认开启,确保第一个 Token 到达即开始显示
优化 Token 间延迟:
- 思维链模式选择:
reasoningMode: "stream"实时显示思考过程,比"hidden"模式让用户等待更少 - 避免阻塞式工具调用:第 4.4.4 节的压缩与流式协调机制确保压缩操作在流式间隙执行
大规模并发处理
OpenClaw 面对的并发挑战与传统 Web 服务不同——瓶颈不在 CPU 或内存,而在 LLM API 的速率限制(RPM/TPM) 和 每次调用的高延迟(秒级):
- Provider 级别速率控制:不同 Provider 有独立的速率限制。配置多个 Provider 并利用第 4 章的故障转移机制,可以突破单一供应商的限制
- 请求排队:当并发请求超过 API 限额时,OpenClaw 的重试基础设施(上一节 15.8.5)配合指数退避自动排队
- 会话隔离:第 5 章的会话管理确保并发对话的上下文互不干扰——100 个用户同时对话,每个都有独立的上下文窗口
- 子 Agent 并发:第 18 章的扇出编排模式允许多个子 Agent 并行处理独立子任务,但需注意总 RPM 消耗
缓存策略
OpenClaw 在多个层面实施缓存:
- 模型目录缓存:
modelCatalogPromise(第 4 章)的 Promise 单例模式避免重复发现 - Provider 能力缓存:
resolveProviderCapabilities缓存已发现的能力,useCache: false可强制刷新 - LLM Prompt 缓存:利用 Anthropic/OpenAI 的原生 prompt caching——相同前缀的请求缓存命中后成本降低 90%
- 文件系统缓存:
models.json文件作为本地缓存,原子写入避免竞态 - 连接复用:HTTP Keep-Alive 和连接池减少 TLS 握手开销
💡 运维建议:Prompt caching 的命中率是成本优化的关键指标。保持系统提示和技能文本稳定(避免频繁修改)可以显著提高缓存命中率。如果你发现
cacheRead指标持续为零,检查是否频繁变更了 AGENTS.md 或 SOUL.md 内容。
15.8.7 故障排查指南
生产环境中的故障排查需要系统化的方法。以下是 OpenClaw 运维中最常见的问题、诊断路径和解决方案。
常见错误消息速查表
| 错误消息 | 含义 | 解决方案 |
|---|---|---|
Gateway not running | Gateway 守护进程未启动 | 执行 openclaw gateway start |
ECONNREFUSED 127.0.0.1:3577 | Gateway 端口未监听 | 检查是否有端口冲突:lsof -i :3577 |
401 Unauthorized (Provider) | API 密钥无效或过期 | 运行 openclaw auth 重新配置凭证 |
429 Too Many Requests | 超过 Provider 速率限制 | 等待冷却期或切换到备用 Provider |
Context window exceeded | 上下文超过模型窗口限制 | 降低 agentContextTokens 或切换到更大窗口的模型 |
SSRF blocked | 出站请求被 SSRF 防护拦截 | 检查目标地址是否为私有 IP 或受限域名 |
Pairing required | Node 设备未完成配对 | 在设备上重新扫描配对码 |
Channel ERROR | 通道连接断开 | 检查对应通道的 Token/Webhook 配置 |
ENOSPC | 磁盘空间不足 | 清理日志文件:openclaw gateway logs --rotate |
SIGTERM received | 进程被系统终止 | 检查 OOM Killer 或 systemd 超时设置 |
诊断分层方法
按照从外到内的顺序排查:
第 1 层 — 进程与服务
└─ Gateway 是否在运行?
└─ systemd 状态是否正常?
└─ 端口是否在监听?
第 2 层 — 网络与通道
└─ 各通道连接状态?
└─ Provider API 是否可达?
└─ DNS 解析是否正常?
第 3 层 — 配置与认证
└─ API 密钥是否有效?
└─ 配置文件语法是否正确?
└─ 环境变量是否已设置?
第 4 层 — 逻辑与行为
└─ Agent 指令是否正确?
└─ 技能是否正确加载?
└─ 工具权限是否配置?日志分析实用命令
# 查看最近的错误日志
cat ~/.openclaw/logs/gateway.log | jq 'select(._meta.logLevelName == "ERROR")' | tail -20
# 按子系统过滤日志
cat ~/.openclaw/logs/gateway.log | jq 'select(.subsystem == "discord")' | tail -20
# 查看特定时间范围的日志
cat ~/.openclaw/logs/gateway.log | jq \
'select(.timestamp >= "2024-01-15T10:00:00" and .timestamp <= "2024-01-15T11:00:00")'
# 统计各级别日志数量
cat ~/.openclaw/logs/gateway.log | jq -r '._meta.logLevelName' | sort | uniq -c | sort -rn
# 追踪特定会话的完整生命周期
cat ~/.openclaw/logs/gateway.log | jq 'select(.sessionId == "sess_xxx")'
# 实时监控日志(类似 tail -f)
tail -f ~/.openclaw/logs/gateway.log | jq '.'调试技巧
提升日志级别:通过环境变量临时开启详细日志
bashOPENCLAW_LOG_LEVEL=debug openclaw gateway startTUI 内调试:使用
/verbose on和/reasoning stream实时观察 Agent 推理过程Bang 模式本地诊断:在 TUI 中用
!curl或!ping直接诊断网络问题,不消耗 Token健康检查端点:访问 Gateway 的健康检查端点获取结构化诊断信息
bashcurl http://localhost:3577/health | jq '.'配置验证:使用
openclaw doctor自动检查常见配置问题
⚠️ 生产环境调试注意:开启
debug级别日志会显著增加日志量(10-50x),可能快速填满磁盘。建议设置OPENCLAW_LOG_LEVEL=debug仅在排查期间使用,排查完毕后恢复默认级别。
15.9 Dockerfile 构建优化细节
15.9.1 BuildKit 缓存挂载
RUN --mount=type=cache,target=/root/.npm \
npm ci --frozen-lockfileBuildKit 的缓存挂载让 npm 的下载缓存在多次构建之间持久化——即使 npm ci 因为 lockfile 变化而重新安装所有依赖,已下载的包仍然在缓存中,不需要重新从 registry 下载。
15.9.2 Bun 安装的重试机制
OpenClaw 的 Docker 构建包含 Bun 运行时安装的 5 次指数退避重试:
for i in 1 2 3 4 5; do
curl -fsSL https://bun.sh/install | bash && break
sleep $((2**i))
done为什么需要重试?Bun 的 CDN(bun.sh)偶尔有可用性问题,在 CI 环境中更容易遇到。5 次重试(总等待约 62 秒)足以覆盖绝大多数临时故障。
15.9.3 .dockerignore 的重要性
一个常常遭到忽略的优化点——.dockerignore 文件排除 node_modules、.git、测试文件等不需要进入构建上下文的内容。对于 OpenClaw 的代码库,这可以将构建上下文从 ~2GB 缩减到 ~50MB,显著加速 docker build 的初始传输阶段。
15.10 实战推演:从零到生产的完整部署
让我们走一遍从裸机到生产级部署的完整流程,在每一步中标注"为什么这样做"。
15.10.1 场景
你有一台 Hetzner VPS(4核 8GB,Ubuntu 22.04),要部署一个连接 Telegram 和 Discord 的个人 Agent。
15.10.2 部署脚本(带注释)
#!/bin/bash
set -euo pipefail # 任何错误立即停止——部署脚本不能"差不多行"
# 1. 创建非 root 用户 —— 最小权限原则
useradd -m -s /bin/bash openclaw
su - openclaw
# 2. 安装 Node.js 22+ —— 使用 nvm 避免 sudo 安装
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.0/install.sh | bash
source ~/.bashrc
nvm install 22
# 3. 安装 OpenClaw + Chromium(浏览器自动化需要)
npm install -g openclaw
npx playwright install chromium --with-deps
# 4. 非交互式配置 —— CI/CD 友好
openclaw setup --non-interactive \
--provider anthropic \
--api-key "$ANTHROPIC_API_KEY" \
--accept-risk
# 5. 配置通道(API Key 通过环境变量,不在配置文件中)
openclaw config set channels.telegram.token "$TELEGRAM_BOT_TOKEN"
openclaw config set channels.discord.token "$DISCORD_BOT_TOKEN"
# 6. 安全加固
openclaw config set gateway.bind "127.0.0.1" # 只监听本地——通过 Caddy 反代暴露
openclaw config set exec.mode "allowlist" # 命令执行白名单模式
openclaw security audit --fix # 自动修复权限问题
# 7. 注册为系统服务 + 启用 linger(注销后仍运行)
openclaw gateway start --install
loginctl enable-linger openclaw
# 8. 配置防火墙
sudo ufw allow 22/tcp # SSH
sudo ufw allow 443/tcp # Caddy HTTPS
sudo ufw default deny incoming
sudo ufw enable
# 9. 验证
openclaw gateway status # 应该显示 running
openclaw doctor # 应该全绿15.10.3 每个决策的安全影响
| 步骤 | 如果省略会怎样 |
|---|---|
| 非 root 用户 | 攻击者突破 Agent 后获得 root 权限 |
| 绑定 127.0.0.1 | 任何人可以直接连接 Gateway |
| allowlist 模式 | Agent 可以执行任意命令(包括 rm -rf /) |
security audit --fix | 配置文件可能 world-readable(密钥泄露) |
| enable-linger | SSH 断开后服务停止 |
| 防火墙 | Gateway 端口直接暴露在公网 |
部署不是把代码放到服务器上就完事了——它是把代码放到一个敌意环境中并确保它能自我保护。互联网上的每台服务器每天都在被扫描、被探测、被尝试入侵。你的部署脚本不仅是在安装软件,更是在构筑防线。每一行配置都在回答一个问题:"如果有人试图攻击这里,会发生什么?"
15.11 框架对比
| 特性 | OpenClaw | LangServe | Dify | AutoGPT |
|---|---|---|---|---|
| 多阶段 Docker 构建 | ✅ 4 阶段 + 双变体 | ✅ 2 阶段 | ✅ | 部分 |
| 非 root 执行 | ✅ | 不确定 | ✅ | ❌ |
| 结构化日志 | ✅ JSON Lines + 子系统着色 | 部分 | 部分 | ❌ |
| 日志脱敏(17 种模式) | ✅ | ❌ | 部分 | ❌ |
| 热重启与延迟 | ✅ SIGUSR1 + 合并 + 5min 超时 | ❌ | ❌ | ❌ |
| 跨平台服务 | ✅ systemd/launchd/schtasks | ❌ | ❌ | ❌ |
| SSRF 防护 | ✅ IPv4 + IPv6 | ❌ | ✅ | ❌ |
| 健康检查端点 | ✅ 结构化状态 | ✅ 基础 | ✅ | ❌ |
| 状态迁移 | ✅ 自动无损升级 | ❌ | ✅ | ❌ |
| 备份恢复 | ✅ CLI 命令 | ❌ | 部分 | ❌ |
| 配置变更审计 | ✅ 字段级 diff | ❌ | ❌ | ❌ |
15.11 关键源码文件
| 文件 | 用途 |
|---|---|
Dockerfile | 多阶段构建 |
docker-compose.yml | 双容器编排 |
src/logging/logger.ts | 日志核心——双输出、滚动、大小限制 |
src/logging/redact.ts | 自动脱敏(17 种模式) |
src/logging/config.ts | 日志配置加载 |
src/logging/levels.ts | 日志级别定义和标准化 |
src/logging/env-log-level.ts | 环境变量级别覆盖 |
src/logging/console.ts | 控制台输出样式 |
src/daemon/service.ts | 统一服务管理接口 |
src/daemon/systemd.ts | Linux systemd 适配 |
src/daemon/systemd-unit.ts | systemd unit 文件生成 |
src/daemon/systemd-linger.ts | systemd linger 管理 |
src/daemon/launchd.ts | macOS launchd 适配 |
src/daemon/launchd-plist.ts | launchd plist 文件生成 |
src/daemon/schtasks.ts | Windows 计划任务适配 |
src/daemon/constants.ts | 跨平台服务常量 |
src/daemon/diagnostics.ts | 服务诊断 |
src/infra/net/ssrf.ts | SSRF 防护 |
src/infra/backoff.ts | 指数退避重试 |
src/infra/backup-create.ts | 备份创建 |
src/infra/archive-staging.ts | 归档暂存 |
src/gateway/channel-health-monitor.ts | 通道健康监控 |
src/gateway/config-reload.ts | 配置热重载和变更审计 |
15.12 本章小结
OpenClaw 的部署与运维架构将生产就绪视为一等关注点。让我们回顾核心设计决策和它们之间的内在联系:
三种部署模型共存。裸机、系统服务、容器化——不是演进替代关系,而是适应不同场景的并行方案。从树莓派上的个人 Agent 到企业 Kubernetes 集群,同一套代码适应所有环境。
日志系统的安全默认。17 种脱敏模式 + SecretRef(第 13 章)形成双重防线。JSON Lines 格式兼顾人类可读和机器可查。永不崩溃的写入策略确保日志问题不会扩散为服务故障。
优雅重启的工程细节。SIGUSR1 信号避免意外触发,5 分钟延迟保护进行中的 LLM 调用,30 秒合并窗口防止频繁重启,跨平台服务管理统一操作体验。
可观测性的多层设计。健康检查端点(进程级)+ 通道健康监控(通道级)+ 配置变更审计(操作级)——三个层面共同提供"系统现在怎么样?"的完整答案。
Docker 的安全工程。四阶段构建优化镜像体积,非 root + cap_drop + no-new-privileges 落实最小权限,GPG 验证保障供应链安全。
核心洞察:生产就绪不是最后添加的功能——它是从一开始就渗透每个设计决策的品质。日志系统的脱敏规则影响了配置文件的格式(SecretRef 而非明文)。重启系统的延迟机制影响了 LLM 调用的超时设计。Docker 的非 root 执行影响了文件路径的选择(/home/node/.openclaw 而非 /root/.openclaw)。SSRF 防护影响了工具系统的网络访问接口(所有出站请求必须经过 isBlockedHostnameOrIp 检查)。这些横切关注点不是独立的"运维功能"——它们是系统架构的有机组成部分。
造就"开发中可用"与"生产中可靠"之间差异的,不是某一个大功能,而是一百个小细节。 谁会在乎日志着色用的是字符串哈希还是固定映射?——凌晨三点 SSH 到远程服务器的你会在乎。颜色一致、结构清晰、敏感信息已脱敏——那一刻,你会感谢每一个"微不足道"的决定。
本章解决了"Agent 在哪里跑"。下一章回答"Agent 怎么变得更聪明"——技能系统。基础设施给了 Agent 生存的土壤,技能给了它进化的阶梯。
思考题
- 概念理解:OpenClaw 的跨平台 Daemon 管理为什么要统一封装 systemd/launchd/schtasks,而不是让用户直接使用各平台原生工具?这种抽象的成本是什么?
- 实践应用:设计一个 OpenClaw 的高可用部署方案——当主节点宕机时,备份节点能在 30 秒内接管所有通道连接。你会面临哪些技术挑战(会话状态迁移、通道重连、配置同步)?
- 开放讨论:对于个人开发者和小团队,"在自己的机器上跑 Agent"与"使用云端 Agent 服务"各有什么利弊?OpenClaw 的本地部署定位在未来会如何演变?
📚 推荐阅读
- Docker 多阶段构建最佳实践 — Docker 官方的构建优化指南
- The Twelve-Factor App — 现代 SaaS 应用部署的十二要素方法论
- Prometheus 监控实践 — 可观测性系统设计的业界标准